
Improving Node.js server response became urgent when users started reporting delays. Some routes took longer than expected, especially under traffic spikes.
Our backend looked fine on the surface, but deep down, slow middleware, unindexed queries, and blocking code were holding it back.
Instead of adding more hardware, we focused on optimizing what we had. Step by step, we identified bottlenecks, cleaned up the code, and monitored improvements.
This article explains how we improved Node.js server response and made it faster, lighter, and more reliable using smart, practical changes.
Step-by-Step Guide to Fixing Node.js Server Response Issues
Here’s a step-by-step look at how we fixed response issues in our Node.js server. This guide helps you to cut response times and boost performance without changing our infrastructure.
Measuring the Pain Before Fixing It
It made no sense to start fixing performance without knowing what exactly was wrong.
So the first step was measurement. We used Postman monitors for basic response times and New Relic for deeper server analytics.
Logs showed that some requests were taking over 1.5 seconds, even though they were not very complex.
We noticed a pattern where requests with external API calls or nested database operations were the slowest.
One endpoint was pulling too much data and trying to process it all in memory.
Another delay came from how we were handling asynchronous functions, many of which were still chained promises instead of clean async/await code.
This gave us a solid baseline. We knew where time was being spent and where improvement would make the most difference.
Once the diagnosis was clear, the fixing phase became more targeted and effective.

Cleaning Up Middleware That Slowed Us Down
Looking into middleware turned out to be more revealing than expected. Our Express.js setup had several old middlewares added for testing, debugging, and logging.
Over time, these piled up and started slowing down requests without anyone noticing. One logging middleware was writing to disk even for small GET requests.
Another was doing schema validation for routes that did not even need it. We cleaned out anything that was not strictly needed in production.
Some middlewares were replaced with lighter alternatives. For example, we switched from a general-purpose validator to a custom one for specific endpoints.
These changes did not change business logic at all, but the effect on speed was immediate.
Response times became shorter, and the CPU was under less pressure. This part of the improvement was simple but very effective.
Making Database Queries Faster with Indexing
A lot of time was being wasted on database queries. We use MongoDB, and while it handles large volumes well, it needs indexes to be fast.
Some of our slowest queries were using text search or sorting on fields with no indexes. That meant full collection scans, even for small requests.
We added indexes to user ID, email, and other commonly searched fields.
One major improvement came from removing the population of referenced documents where it was not absolutely necessary.
In places where we only needed the ID or a single value, we avoided joining collections.
We also simplified queries that were fetching too many fields or applying multiple filters.
After these changes, read times went down sharply. Queries that used to take 800 milliseconds were now returning results in under 200 milliseconds.
This database tuning was one of the most powerful fixes we made.

Switching to Asynchronous Patterns More Effectively
Our code had grown over time, and with that came inconsistency in how we handled async tasks.
Some functions used nested .then() chains, while others used async/await but in blocking sequences.
This led to unnecessary wait times, especially when tasks could run in parallel. We refactored the code to follow a consistent async/await pattern.
More importantly, we looked for tasks that could happen at the same time and used Promise.all() or concurrency tools like p-limit to manage them.
For example, fetching user data and log history no longer wait for each other unless one depends on the other.
This single change made a huge difference on routes with multiple external requests.
Once the async logic became cleaner and more efficient, we noticed a sharp drop in server delay across various routes.
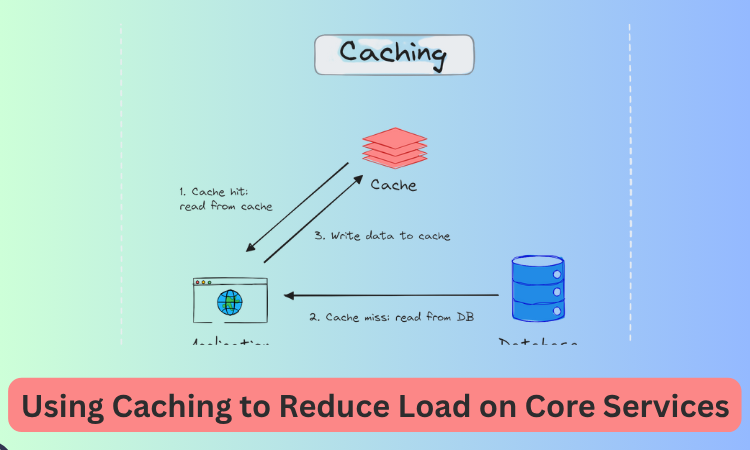
Using Caching to Reduce Load on Core Services
We decided to reduce pressure on the server by adding caching where possible.
Redis was added as a caching layer for common queries like user settings, authentication tokens, and configuration data.
These were things that rarely changed but were requested frequently.
Setting a reasonable time-to-live (TTL) on each cache entry, we made sure the data stayed fresh without hitting the database every time.
We also cached responses from third-party APIs when possible, especially when the API provider had a limit on request frequency.
The result was that repeated requests for the same data were served much faster, and our Node.js server had more room to handle complex tasks.
This change not only improved speed but also gave us better control over traffic during peak times.
Keeping Monitoring and Logs Smart, Not Heavy
Once performance improved, we had to make sure it stayed that way. This meant rethinking how we monitored our server.
The old logging system was capturing too much detail and writing it all to disk. During load, this became a burden.
We changed the logging format and only kept logs that were actually useful in production.
For error tracking, we used tools like Sentry to focus on real issues instead of clutter.
Alerts were set up to notify us only if something crossed a performance threshold.
This smarter approach to monitoring helped us stay focused without drowning in noise.
Now if something starts slowing down again, we can catch it early and fix it fast. It also makes our daily monitoring easier to manage.
The Outcome of All These Changes
After completing all the optimizations, we started seeing results within a few days. The average response time dropped from over 700 milliseconds to just under 300 milliseconds.
Routes that previously lagged were now quick and responsive. More users could connect at the same time without any extra server cost.
Our support team reported fewer performance-related complaints. What made this success special was that we achieved it using the same infrastructure, just smarter code.
It showed us how much potential was being wasted earlier. These improvements also made our developers more careful about performance during future updates. Now, every feature is checked for speed before going live.

Web development often looks smooth on the surface, but real issues start when things break or slow down.
BrandOut focuses on fixing those hidden problems, slow backend, messy code, or server errors.
Instead of temporary patches, we offer practical solutions that improve how your site works. If your project feels stuck, BrandOut helps move it forward with clarity and speed.
To sum it up
Improving a Node.js server is not about applying one magic fix. It is about fixing many small things that together make a big difference.
From cleaning middleware to caching, from refactoring async code to smart logging, every step played its part.
What worked best for us was tracking metrics, fixing one area at a time, and always testing before and after.
These changes not only improved user experience but also made the backend more stable and scalable.
Any team facing performance issues can benefit from these lessons. Start with what you have, measure everything, and improve patiently. That is the real key to faster servers.
Answer to the popular questions:
How to get better at NodeJS?
Getting better at NodeJS takes practice and consistency. Start with small apps, then move to complex projects.
Focus on how asynchronous programming works, especially promises and async/await. Learn how Node handles non-blocking operations.
Read NodeJS documentation and explore its core modules like fs, http, and events. Use tools like ESLint and nodemon to write better code.
Watch tutorials, join forums, and try contributing to open-source. The more you build and debug, the faster your learning will grow.
How to reduce latency in NodeJS?
To reduce latency in NodeJS, first look at your database queries. Use indexes and avoid unnecessary joins. Add Redis caching for repeated data.
Remove extra middleware from your routes. Avoid blocking code and use async functions properly.
Try to process background tasks in queues instead of doing everything in the main thread.
Also, use performance monitoring tools like Prometheus to spot slow areas. These steps help in keeping the server fast, even when the traffic increases.
How to speed up Node build?
Speeding up your Node build starts with using fewer and smaller dependencies. Avoid installing unused packages.
Switch to faster compilers like esbuild or swc if you are using Babel. Keep your build scripts clean and skip unnecessary steps.
Enable build caching in CI/CD pipelines. Also, tree-shake your code to remove unused modules during bundling.
Keeping the project structure organized also helps the build process run faster. All these changes can reduce build time without hurting functionality.
How to speed up backend?
Speeding up the backend starts with optimizing database access. Use indexes, avoid large queries, and load only what is needed.
Add caching for data that does not change often. Keep middleware short and meaningful. Run tasks like image processing or emails in background queues.
Minimize the number of third-party API calls and do them in parallel if needed. Use connection pooling and compression.
Each of these changes can make the backend more responsive and capable of handling more users.
What is faster than Node?
Languages like Go, Rust, and C++ are generally faster than Node because they are compiled and close to the system.
Go is popular for web servers and microservices due to its speed and simplicity. Rust offers
high performance with memory safety.
C++ is extremely fast but harder to manage. Still, Node remains a top choice for web apps because of its non-blocking nature and large ecosystem.
The right architecture and code quality often matter more than the language itself.


